DDL-сценарий генерации схемы базы данных
22. DDL-сценарий генерации схемы базы данных

Далее можно попытаться снова воспользоваться Data Migration Wizard для переноса данных, отказываясь при этом от удаления уже сгенерированных таблиц. Однако в ряде случаев удобнее создать приложение для переноса данных из старой БД в новую. Как было отмечено выше, унаследованные данные могут не удовлетворять правилам ссылочной целостности, установленным на сервере. В этом случае от приложения, используемого для переноса данных, требуется некоторая гибкость (например, предоставление возможности редактирования исходных данных или создание дополнительных таблиц, содержащих записи, не удовлетворяющие бизнес-правилам новой базы данных, для последующего анализа).
Создадим простейшее приложение для переноса данных. Для этого создадим форму следующего вида (рис.23):
Диагностическое сообщение при...
25. Диагностическое сообщение при попытке удаления записей из master-таблицы при наличии связанных с ней записей в detail-таблице.

Точно так же окажется невозможным добавить запись с произвольным значением поля ACC_NBR в таблицу HOLDINGS. Причина такого поведения созданной информационной системы очевидна: при проектировании базы данных с помощью ERwin помимо самих таблиц и индексов были созданы также специальные объекты базы данных, называемые триггерами. Триггер - это специальная процедура, выполняющаяся при наступлении определенного события, например, при попытке удаления записи в таблице CLIENTS. При описании свойств связи между таблицами мы выбирали, как сервер будет реагировать на подобные события, и в соответствии с нашим выбором были сгенерированы триггеры для выполнения соответствующих действий (в данном случае - для передачи клиентскому приложению диагностического сообщения).
Разумеется, пользователь приложения должен видеть нечто более вразумительное, нежели англоязычное сообщение с именем триггера и словами про "integrity constraint" и "key violation". Можно сделать это путем перехвата исключения в клиентском приложении, но более предпочтительно делать это на сервере, так как тогда будет исключена необходимость в повторении кода в случае, когда с одной и той же базой данных работают несколько приложений. Современные CASE-средства позволяют это сделать, и интересующиеся этой проблемой могут найти ее решение в документации по используемому CASE-средству и в документации, прилагаемой к соответствующему серверу баз данных.
Диагностическое сообщение при попытке добавления записей в detail-таблицу при пустой master-таблице.
24. Диагностическое сообщение при попытке добавления записей в detail-таблицу при пустой master-таблице.

Примерно такие же последствия будет иметь попытка очистить таблицу CLIENTS после того, как перенесены записи в таблицу HOLDINGS.
После переноса данных на сервер можно вернуться к созданному ранее приложению с формой master-detail и попробовать снова проделать действия, приводящие к нарушению ссылочной целостности.
Теперь, если мы попытаемся удалить запись из таблицы CLIENTS при наличии связанных с ней записей в таблице HOLDINGS, нам это не удастся. При этом клиентским приложением будет выдано диагностическое сообщение о наличии записей в дочерней таблице (рис. 25):
Этап 1: модель "хост-компьютер + терминалы"
1. Этап 1: модель "хост-компьютер + терминалы"
Этот подход, весьма прогрессивный по тем временам, обладал некоторыми несомненными достоинствами. Во-первых, пользователи такой системы могли совместно использовать различные ресурсы хост-компьютера (оперативную память, процессор) и довольно дорогие для тех времен периферийные устройства (принтеры, графопостроители, устройства ввода с магнитных лент и гибких дисков, перфосчитыватели, дисковые накопители и иное оборудование, кажущееся по теперешним временам довольно экзотическим). Разумеется, используемые при этом операционные системы поддерживали многопользовательский многозадачный режим. Во-вторых, централизация ресурсов и оборудования облегчала и удешевляла эксплуатацию такой системы.
В чем были недостатки подобной архитектуры вычислений? Главным образом в полной зависимости пользователя от администратора хост-компьютера. Фактически пользователь (а нередко и программист) не имел возможности настроить рабочую среду под свои потребности – используемое программное обеспечение, в том числе и текстовые редакторы, компиляторы, СУБД, целиком и полностью было коллективным.
Не будет, наверное, большим преувеличением сказать, что в значительной степени именно этот недостаток подобных систем привел к бурному (и не прекратившемуся до сих пор) развитию индустрии персональных компьютеров. Наряду с дешевизной и простотой эксплуатации достаточно привлекательной особенностью настольных информационных систем стала так называемая персонализация рабочей среды, когда пользователь мог выбрать для себя инструменты для работы (текстовый редактор, СУБД, электронную таблицу и др.), наиболее соответствующие его потребностям. Естественно, и инструментов этих на рынке программных продуктов появилось довольно много. Именно в этот период появились электронные таблицы и настольные СУБД (dBase, FoxBase, Сlipper, Paradox и др.), нередко совмещающие в себе собственно СУБД и средства разработки приложений, использующих базы данных.
Этап 2: автономная персональная обработка данных
2. Этап 2: автономная персональная обработка данных

Следующим этапом развития архитектуры информационных систем было появление сетевых версий вышеупомянутых СУБД, позволяющих осуществлять многопользовательскую работу с общими данными в локальной сети. Этот подход сочетал в себе как удобства персонализации пользовательской среды и простоты эксплуатации, так и преимущества, связанные со вновь открывшимися возможностями совместного использования периферии (главным образом сетевых принтеров и сетевых дисков, в том числе хранящих коллективные данные). Отметим, что большинство информационных систем, реально эксплуатируемых сегодня в нашей стране, имеют именно такую архитектуру (в том числе некоторые информационные системы, реализованные на Delphi и C++Builder), и в случае не очень большого количества пользователей системы, не слишком большого объема данных и количества таблиц, невысоких требований к защите данных этот подход себя, безусловно, оправдывает.
Этап 3: коллективная обработка данных с использованием сетевых версий настольных СУБД и файлового сервера
3. Этап 3: коллективная обработка данных с использованием сетевых версий настольных СУБД и файлового сервера
Недостатки использования сетевых версий настольных СУБД обычно начинают проявляться в процессе длительной эксплуатации информационной системы, когда со временем увеличивается объем введенных пользователями данных, а иногда и число пользователей. Обычно в первую очередь замечается снижение производительности работы приложений, хотя нередко возникают и иные сбои в работе (например, разрушение индексов, нарушение ссылочной целостности данных). Причины этих явлений кроются в самой концепции хранения коллективных данных в файлах на сетевом диске и сосредоточении всей обработки данных внутри пользовательского приложения.
Возьмем простой пример. Допустим, пользователю нужно выбрать по какому-то признаку пять записей из таблицы, содержащей всего миллион подобных записей. Как происходит обработка данных при выполнении такого запроса с использованием коллективных файлов? Путем перебора записей и поиска нужных согласно какому-либо алгоритму, возможно, с использованием облегчающих поиск индексов. В любом случае этим занимается приложение, функционирующее на компьютере пользователя, и, следовательно, файлы или их части, нужные для поиска данных, фактически передаются по сети от файлового сервера к компьютеру пользователя. Поэтому при большом количестве данных и пользователей, а также при наличии многотабличных запросов пропускная способность сети может перестать удовлетворять предъявляемым к ней требованиям, связанным с эксплуатацией такой информационной системы.
Возросший сетевой трафик – не единственная неприятность, подстерегающая администратора и разработчика подобной информационной системы. Весьма частым явлением в этом случае является нарушение ссылочной целостности данных. Возьмем уже ставший классическим пример, приводимый во всех учебниках по базам данных. Имеются две таблицы формата dBase: список заказчиков какой-либо компании, и список их заказов, связанные по какому-либо полю, например, CUST_ID (рис.4). Вполне разумными требованиями, предъявляемыми к такой БД (иногда называемыми бизнес-правилами), являются уникальность значений этого поля в списке заказчиков (иначе как узнать, чьи заказы с этим CUST_ID находятся в таблице заказов?), и отсутствие в списке заказов записей со значениями CUST_ID, отсутствующими в таблице заказчиков (то есть “ничьих” заказов). В случае dBase выполнение таких требований реализуется на уровне логики приложения. При этом практически всегда имеется возможность произвольного редактирования таблиц иными средствами (от dBase III до обычных текстовых редакторов), что может привести к нарушению этих требований. Обычно для предотвращения подобных прецедентов используются различные организационно-технические меры, например, запрещение средствами сетевой ОС доступа к файлам с таблицами иначе как из конкретного приложения. При этом полной гарантии сохранения ссылочной целостности все равно нет, так как остается вероятность так называемых незавершенных транзакций (то есть попытки согласованного изменения данных в нескольких таблицах – например, удаления заказчика вместе со всеми его заказами, во время которого произошел сбой питания, в результате чего удалилась только часть данных). Отметим также, что если информационная система содержит несколько приложений, использующих общие данные, каждое из них должно содержать код, предотвращающий некорректное с точки зрения ссылочной целостности изменение данных.
Этап 4: обработка данных в архитектуре клиент/сервер
5. Этап 4: обработка данных в архитектуре клиент/сервер

В чем преимущества клиент-серверных информационных систем по сравнению с их аналогами, созданными на основе сетевых версий настольных СУБД?
Одним из важнейших преимуществ является снижение сетевого трафика при выполнении запросов Например, при необходимости выбора пяти записей из таблицы, содержащей миллион, клиентское приложение посылает серверу запрос, который сервером компилируется и выполняется, после чего результат запроса (те самые пять записей, а вовсе не вся таблица) передается обратно на рабочую станцию (если, конечно, клиентское приложение корректно формулирует запросы к серверу, о чем мы поговорим в следующих статьях цикла).
Вторым преимуществом архитектуры клиент/сервер является возможность хранения бизнес-правил на сервере, что позволяет избежать дублирования кода в различных приложениях, использующих общую базу данных. Кроме того, в этом случае любое редактирование данных, в том числе и редактирование нештатными средствами, может быть произведено только в рамках этих правил.
Кроме того, для описания серверных бизнес-правил в наиболее типичных ситуациях (как в примере с заказчиками и заказами) существуют весьма удобные инструменты - так называемые CASE-средства (CASE означает Computer-Aided System Engineering), позволяющие описать подобные правила, и создавать реализующие их объекты базы данных (индексы, триггеры), буквально рисуя мышью связи между таблицами без какого бы то ни было программирования. В этом случае клиентское приложение будет избавлено от значительной части кода, связанного с реализацией бизнес-правил непосредственно в приложении. Отметим также, что часть кода, связанного с обработкой данных, также может быть реализована в виде хранимых процедур сервера, что позволяет еще более "облегчить" клиентское приложение, а это означает, что требования к рабочим станциям могут быть не столь высоки. Это в конечном итоге удешевляет стоимость информационной системы даже при использовании дорогостоящей серверной СУБД и мощного сервера баз данных.
Помимо перечисленных возможностей, современные серверные СУБД обладают широкими возможностями управления пользовательскими привилегиями и правами доступа к различным объектам базы данных, резервного копирования и архивации данных, а нередко и оптимизации выполнения запросов. Они также, как правило, предоставляют возможность параллельной обработки данных, особенно в случае использования многопроцессорных компьютеров в качестве сервера баз данных.
Итак, клиент-серверная информационная система состоит в простейшем случае из трех основных компонентов:
сервер баз данных, управляющий хранением данных, доступом и защитой, резервным копированием, отслеживающий целостность данных в соответствии с бизнес-правилами и, самое главное, выполняющий запросы клиента;
клиент, предоставляющий интерфейс пользователя, выполняющий логику приложения, проверяющий допустимость данных, посылающий запросы к серверу и получающий ответы от него;
сеть и коммуникационное программное обеспечение, осуществляющее взаимодействие между клиентом и сервером посредством сетевых протоколов.
Есть и более сложные реализации архитектуры клиент/сервер, например, трехуровневые информационные системы с использованием серверов приложений, но это уже тема отдельного разговора.
Форма приложения для переноса данных на сервер
23. Форма приложения для переноса данных на сервер
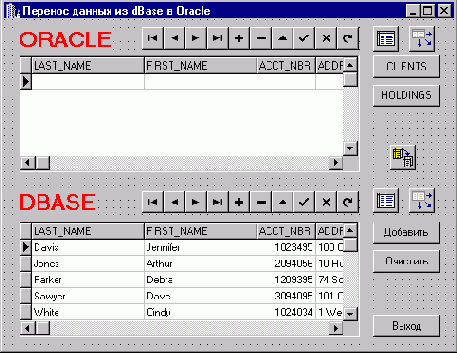
Для переноса данных с одной платформы на другую обычно используется компонент TBatchMove. Этот компонент обеспечивает копирование данных из одной таблицы в другую. Основные свойства этого компонента следующие: Source – таблица (или запрос), откуда копируются данные, Destination – таблица, куда копируются данные, Mapping – определяет соответствие между колонками исходной и результирующей таблиц (для идентичных таблиц это свойство определять не обязательно), Mode – тип перемещения (batAppend – добавляет новые строки в результирующую таблицу, batUpdate – заменяет строки в результирующей таблице на соответствующие строки оригинала, batCopy – копирует строки в результирующую таблицу, переписывая ее, batDelete – удаляет записи в результирующей таблице, соответствующие записям оригинала), KeyViolTableName и ProblemTableName – имена дополнительных таблиц для помещения записей, чье копирование запрещено правилами ссылочной целостности или по каким-либо причинам невозможно (например, из-за несоответствия типов данных), ChangedTableName – имя таблицы для помещения измененных записей. Копирование данных происходит при выполнении метода Execute(). Отметим, что этот метод может быть вызван непосредственно из среды разработки с помощью контекстного меню компонента TBatchMove.
Установим следующие значения свойств используемых компонентов:
| Компонент | Свойство | Значение |
| Table1 | DatabaseName | Oracle7 |
| Exclusive | true | |
| TableName | CLIENTS | |
| Active | true | |
| Table2 | DatabaseName | BCDEMOS |
| TableName | ClLIENTS.DBF | |
| Active | true | |
| DataSource1 | DataSet | Table1 |
| DataSource2 | DataSet | Table2 |
| DBGrid1 | DataSource | DataSource1 |
| DBGrid2 | DataSource | DataSource2 |
| DBNavigator1 | DataSource | DataSource1 |
| DBNavigator2 | DataSource | DataSource2 |
| BatchMove1 | Source | Table2 |
| Destination | Table1 | |
| Mode | batAppend | |
| Button1 | Caption | CLIENTS |
| Button2 | Caption | HOLDINGS |
| Button3 | Caption | Добавить |
| Button4 | Caption | Очистить |
| Button5 | Caption | Выход |
#include <vcl\vcl.h>
#pragma hdrstop
#include "upsize1.h"
//--------------------------------------------------------
#pragma link "Grids"
#pragma resource "*.dfm"
TForm1 *Form1;
//--------------------------------------------------------
__fastcall TForm1::TForm1(TComponent* Owner): TForm(Owner)
{
}
//--------------------------------------------------------
void __fastcall TForm1::Button1Click(TObject *Sender)
{
Table1->Close();
Table2->Close();
Table1->TableName="CLIENTS";
Table2->TableName="CLIENTS.DBF";
Table1->Open();
Table2->Open();
}
//--------------------------------------------------------
void __fastcall TForm1::Button2Click(TObject *Sender)
{
Table1->Close();
Table2->Close();
Table1->TableName="HOLDINGS";
Table2->TableName="HOLDINGS.DBF";
Table1->Open();
Table2->Open();
}
//--------------------------------------------------------
void __fastcall TForm1::Button5Click(TObject *Sender)
{
Table1->EmptyTable();
}
//--------------------------------------------------------
void __fastcall TForm1::Button3Click(TObject *Sender)
{
BatchMove1->Execute();
}
//--------------------------------------------------------
void __fastcall TForm1::Button4Click(TObject *Sender)
{
Close();
}
//-------------------------------------------------------- Скомпилируем и запустим приложение. Кнопки CLIENTS и HOLDINGS осуществляют выбор между той или иной парой таблиц. При нажатии кнопки Добавить происходит перенос данных из активной в данный момент таблицы dBase (CLIENTS или HOLDINGS) в соответствующую таблицу Oracle. Отметим, что наличие поддержки ссылочной целостности можно проверить, попытавшись перенести данные из таблицы HOLDINGS до того, как перенесены данные из таблицы CLIENTS. При этом перенос осуществлен не будет, и в процессе выполнения приложения появится диагностическое сообщение примерно следующего вида (рис.24):
Главная форма приложения после "приведения в порядок"
17. Главная форма приложения после "приведения в порядок"
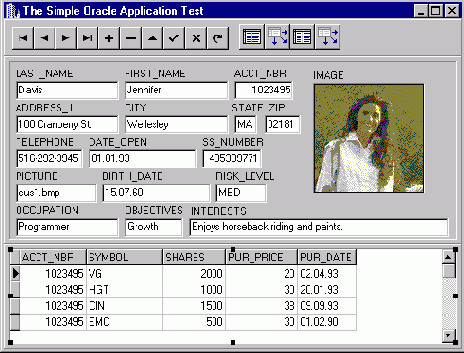
Скомпилируем и запустим созданное приложение и рассмотрим, каким образом созданная информационная система реагирует на изменение данных.
Если мы попытаемся удалить первую запись в таблице CLIENTS, нам это удастся, несмотря на то, что в таблице HOLDINGS есть связанные с ней записи. Точно так же можно добавить запись с произвольным значением поля ACC_NBR в таблицу HOLDINGS, и это нам также удастся. Таким образом, в созданной нами базе данных из двух таблиц связь "один-ко-многим" фактически отсутствует.
Итак, на этом простейшем примере мы убедились, что подобный перенос данных, несмотря на простоту, не всегда приемлем с точки зрения использования всех возможностей серверной СУБД, особенно в случае большого числа таблиц и связей между ними.
Некоторые выводы
Некоторые выводы
Таким образом, архитектура клиент/сервер обладает рядом существенных преимуществ по сравнению с традиционной архитектурой информационных систем, основанных на сетевых версиях настольных СУБД: более высокой производительностью, более низким сетевым трафиком, улучшенными средствами обеспечения безопасности и целостности данных, возможностью задания бизнес-правил. Отметим также, что при использовании современных средств проектирования баз данных, и, в частности, CASE-технологии, разработчик имеет возможность возложить на сервер значительную часть проблем, которые ранее были проблемами самих клиентских приложений, что может существенно облегчить их создание.
Координаты автора: Учебный центр Interface Ltd., тел. (095)135-55-00, 135-25-19,
e-mail: elmanova@interface.ru
Немного истории
Немного истории
Давайте отвлечемся от современных технических средств и программных продуктов, используемых при построении информационных систем, и вспомним, что происходило два десятилетия назад. В те времена при построении информационных систем самой популярной была модель “хост-компьютер + терминалы”, реализованная на базе мэйнфреймов (например, IBM-360/370, или их отечественных аналогов - компьютеров серии ЕС ЭВМ), либо на базе так называемых мини-ЭВМ (например, PDP-11, также имевших отечественный аналог – СМ-4). Характерной особенностью такой системы была полная “неинтеллектуальность” терминалов, используемых в качестве рабочих мест – их работой управлял все тот же хост-компьютер (рис.1)
Описание ODBC-источника с помощью панели управления Windows
18. Описание ODBC-источника с помощью панели управления Windows
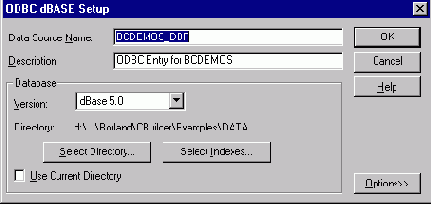
Попробуем осуществить обратное проектирование с помощью ERwin , используя созданный ODBC-источник. Для этого из меню главного окна ERwin выберем опцию Tasks/Reverse Engineering .
Первая проблема, с которой при этом можно столкнуться, заключается в том, что Erwin не поддерживает формат данных dBase 5.0 (с прежними версиями dBase такой проблемы нет), и при обратном проектировании структура таблиц, содержащих графические поля, не всегда восстанавливается. Обычно эта проблема решается путем выбора сходной по структуре платформы (dBase III, Clipper, FoxPro) и последующей коррекции результатов обратного проектирования. Особое внимание при этом следует обращать на специфические типы данных (например, BLOB-поля), так как различия между платформами заключаются, в частности, в способах хранения подобных типов данных (но, разумеется, не только в этом).
Выберем в качестве исходной платформы Clipper, ответим на вопросы, предлагаемые в последующем диалоге (можно оставить то, что предложено по умолчанию) и в результате получим модель данных, похожую на изображенную на рис.19 (она содержит описание всех dBase-таблиц из каталога, содержащего данные для примеров, поставляемых с C++Builder):
Определение реакции сервера на попытки нарушения ссылочной целостности
21. Определение реакции сервера на попытки нарушения ссылочной целостности

После этого можно выбрать из меню опцию Tasks/Forward Engineer/Schema Generation и после установки соединения с Oracle сгенерировать базу данных, выбрав в появившейся диалоговой панели опции для генерации структуры. Можно также просмотреть и сохранить скрипт на языке PL/SQL (это процедурное расширение SQL, используемое для написания триггеров и хранимых процедур Oracle), называемый также DDL-сценарием (DDL расшифровывается как Data Definition Language).
Особенности архитектуры клиент/сервер
Особенности архитектуры клиент/сервер
Что же представляет собой архитектура клиент/сервер? В определенной степени ее можно назвать возвратом к модели “хост-компьютер+терминалы”, так как ядром такой системы является сервер баз данных, представляющий собой приложение, осуществляющее комплекс действий по управлению данными – выполнение запросов, хранение и резервное копирование данных, отслеживание ссылочной целостности, проверку прав и привилегий пользователей, ведение журнала транзакций. При этом в качестве рабочего места может быть использован обычный персональный компьютер, что позволяет не отказываться от привычной рабочей среды.
Перенос унаследованных данных с использованием CASE-средств
Перенос унаследованных данных с использованием CASE-средств
Рассмотрим альтернативный способ переноса данных на сервер, более дорогой и сложный, но приводящий в целом к более качественному результату. Этот способ базируется на использовании CASE-средств (CASE расшифровывается как Computer-Aided System Engineering) для восстановления схемы базы данных по имеющимся таблицам (так называемого обратного проектирования), замены платформы и описания связей между таблицами с точки зрения реакции сервера на попытки того или иного изменения данных со стороны клиентского приложения. В качестве такого средства рассмотрим, например, ERwin 3.0 - CASE-средство компании Logic Works, предназначенное для проектирования баз данных и на сегодняшний день являющееся одним из наиболее простых и доступных по цене средств такого класса.
Прежде чем заняться обратным проектированием, следует описать ODBC-источник, соответствующий каталогу, в котором хранятся исходные dBase-таблицы (это делается с помощью панели управления Windows).
Перенос унаследованных данных с помощью Data Migration Wizard
Перенос унаследованных данных с помощью Data Migration Wizard
Способов переноса данных может быть несколько. Первый, самый примитивный, и, к сожалению, весьма распространенный, представляет собой перенос структур данных и самих данных "как есть" с одной платформы на другую с заменой типов данных настольной СУБД на эквивалентные им типы данных сервера. Этой цели служит утилита Data Migration Wizard, входящая в комплект поставки C++Builder. Рассмотрим ее работу на простом примере из двух связанных таблиц. Для этой цели вполне подойдут таблицы CLIENTS.DBF (список клиентов) и HOLDINGS.DBF (список зданий), связанные отношением "один ко многим". Такой пример выбран потому, что таблица CLIENTS содержит графические и мемо-поля, при переносе которых с платформы на платформу нередко возникают проблемы (в отличие от символьных и числовых полей, для которых обычно можно подобрать эквивалентный тип данных). В качестве серверной СУБД используем 90-дневную trial-версию Personal Oracle 7.2 для Windows 95 или Oracle Workgroup Server 7.2.для Windows NT (в принципе подобный пример можно выполнить и с помощью входящего в комплект поставки С++Builder локального сервера InterBase). Перед тем как выполнить данный пример, запустим сервер и с помощью входящей в комплект поставки утилиты администрирования сервера (в нашем случае Personal Oracle Navigator) опишем пользователя USER1, от имени которого будут создаваться таблицы, проверив заодно наличие соединения с базой данных.
Пример связи "один-ко-многим"
4.Пример связи "один-ко-многим"

Каким образом можно избежать подобных неприятностей? Ответ напрашивается сам собой: еще раз подумать об архитектуре информационной системы и сменить ее, если в обозримом будущем ожидаются подобные прецеденты. Использование серверных СУБД является в этом случае наиболее подходящим решением.
Примерный вид модели данных для генерации БД в Oracle
20. Примерный вид модели данных для генерации БД в Oracle

Теперь можно описать свойства имеющейся связи между таблицами. Так как это связь "один-ко-многим", это следует явно указать в диалоге, вызываемом с помощью опции Relationship Editor контекстного меню связи. В том же диалоге на другой странице трехстраничного блокнота следует выбрать из предлагаемых выпадающих списков возможную реакцию сервера на попытки нарушения ссылочной целостности со стороны клиента. Например, при попытке удалить запись из таблицы CLIENTS можно либо совершить каскадное удаление (то есть удалить все соответствующие записи из таблицы HOLDINGS), либо запретить удаление, если имеются соответствующие записи в дочерней таблице, с выдачей диагностического сообщения.
Результат обратного проектирования каталога CBUILDER\EXAMPLES\DATA
19. Результат обратного проектирования каталога CBUILDER\EXAMPLES\DATA
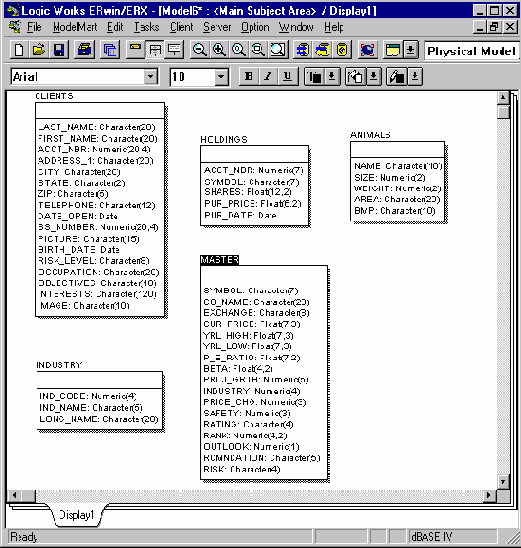
Отредактируем полученную модель данных, убрав все таблицы, кроме CLIENTS и HOLDINGS, определив ACC_NBR первичный ключ таблицы CLIENTS и изменив тип данных поля IMAGE на МЕМО (опция Column Editor контекстного меню таблицы). Создадим также неидентифицирующую связь "один-ко-многим" между таблицами CLIENTS и HOLDINGS, выбрав для этой цели соответствующую пиктограмму на "плавающей" инструментальной панели.
Далее следует выбрать другую целевую платформу (в нашем случае Oracle). В результате получим примерно следующий вид модели данных:
Серверные СУБД и унаследованные данные
Серверные СУБД и унаследованные данные
Одной из наиболее распространенных проблем, связанных с модернизацией эксплуатируемых информационных систем, является использование в них данных, унаследованных от прежних версий и содержащихся, как правило, в форматах настольных СУБД. В частности, вопросы модернизации устаревших систем на основе xBase и переноса их на платформу Oracle, а также этапы модернизации с организационной точки зрения были подробно проанализированы Алексеем Ярцевым в статье "Миграция из xBase в Oracle'' ("Компьютер -Пресс", 1997, N 8, стр.137-140).
В данной работе хотелось бы рассмотреть некоторые технические аспекты проблемы использования унаследованных данных применительно к С++Builder.
Унаследованные данные, представляющие собой, как правило, самое ценное из устаревшей информационной системы, довольно редко удается перенести в серверную СУБД безболезненно. Причин тому может быть много: неудачное проектирование данных, нарушенная ссылочная целостность (причины таких нарушений были изложены выше), наконец, ориентация на иные способы обработки данных, характерные для настольных СУБД и не всегда приемлемые для серверов баз данных.
Создание псевдонима для доступа к данным Oracle
7. Создание псевдонима для доступа к данным Oracle

Отметим, что 2: - имя локального сервера Oracle (при работе с Oracle Workgroup Server for Windows NT, расположенном на том же компьютере, что и С++Builder, можно использовать такое же имя сервера). В случае удаленного сервера следует описать местоположение и доступ к базе данных (имя БД, сетевой протокол, IP-адрес или сетевое имя компьютера) с помощью утилиты SQL*Net Easy Configuration, входящей в комплект поставки серверов Oracle последних версий.
После описания доступа к БД рекомендуется проверить правильность настроек BDE. Это можно сделать, запустив SQL Explorer и попытавшись открыть какую-либо из таблиц Oracle (любая современная серверная СУБД, как правило, содержит какие-либо таблицы в качестве примера). Если список таблиц получить не удается, следует проверить, есть ли в переменной окружения PATH каталог типа С:\ORAWIN95\BIN, и есть ли в каталоге WINDOWS\SYSTEM файлы типа ORA72.DLL или ORANT71.DLL.
После проверки настроек BDE можно приступить непосредственно к переносу таблиц. Запустим Data Migration Wizard:
Список таблиц и индексов, подлежащих переносу.
10. Список таблиц и индексов, подлежащих переносу.

Если нажать кнопку Modify Mapping Information For Selected Item, получим сведения о том, в какие типы данных будут преобразованы поля исходных таблиц. При необходимости в эти сведения можно внести правки.
Установка связи между таблицами
15. Установка связи между таблицами
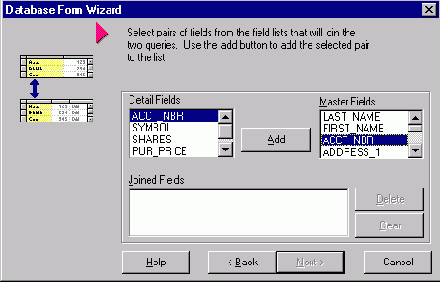
Далее выбираем опцию Generate a Main Form и в результате получим форму, похожую на представленную на рис. 16:
Внесение правок в правила преобразования полей
11. Внесение правок в правила преобразования полей

После внесения правок можно вернуться к предыдущему экрану и нажать кнопку Upsize. После этого начнется процесс создания на сервере таблиц и индексов и копирования данных, и по окончании процесса можно получить отчет о результатах.
Достоинством этого метода переноса данных является его простота. Но при его применении далеко не все преимущества архитектуры клиент/сервер оказываются использованными. Скорость выполнения запросов к данным, хранящимся теперь в серверной базе данных, действительно может возрасти - их будет выполнять сервер. Однако, перенося данные таким способом, мы создали на сервере только то, что было в исходной базе данных - таблицы и индексы. Новые объекты серверной базы данных, реализующие бизнес-правила, такие, как триггеры и хранимые процедуры, при этом созданы не будут - их придется создавать вручную, занимаясь кодированием на процедурном расширении SQL, характерном для данного сервера, либо, как и в случае настольных СУБД, описывать их внутри клиентского приложения, рискуя нарушить ссылочную целостность данных. Если мы попытаемся создать приложение, работающее с только что созданными нами таблицами, то сумеем в этом убедиться.
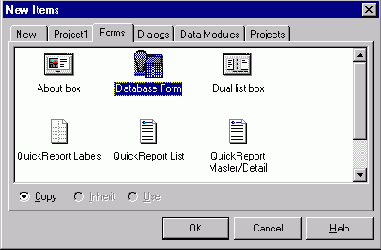
Для создания такого приложения воспользуемся инструментом под названием Database Form Wizard. Запустим C++Builder, создадим новый проект, удалим из него пустую форму и выберем со страницы Forms репозитария объект Database Form:
Вот что обычно получается при использовании Database Form Wizard
16. Вот что обычно получается при использовании Database Form Wizard

После редактирования и открытия таблиц, изменения размеров формы и панелей, а также замены компонента TDBEdit, отображающего поле IMAGE, на TDBimage, получим форму, похожую на рис.17:
Современные средства разработки информационных систем,
Введение
Современные средства разработки информационных систем, к числу которых относится C++Builder, ориентированы на широкую поддержку различных СУБД, как настольных, так и серверных. Построение эффективных и надежных с точки зрения сохранности и защиты данных многопользовательских информационных систем, как правило, производится с использованием последних. Создание приложений в архитектуре клиент/сервер с помощью C++ Builder обладает рядом особенностей, отличающих их от приложений, использующих настольные СУБД. Эти особенности и будут рассмотрены в ближайших нескольких статьях данного цикла.
Выбор Database Form из репозитария С++Builder
12. Выбор Database Form из репозитария С++Builder
Далее выберем создание формы master/detail c использованием объектов TTable:
Выбор исходной БД в Data Migration Wizard
8. Выбор исходной БД в Data Migration Wizard
Далее выберем псевдоним БД, в которую мы осуществляем экспорт данных, и затем выберем имена экспортируемых таблиц:
Выбор master-таблицы
14. Выбор master-таблицы

Затем определим, какие поля этой таблицы нам нужны (можно выбрать все), и как они будут расположены на форме (выберем горизонтальное расположение полей). Затем определим detail-таблицу (в данном случае HOLDINGS), выберем все поля и в качестве способа их отображения выберем размещение их в TDBGrid. Наконец, укажем, что таблицы связаны по полю ACCT_NBR:
Выбор таблиц для переноса данных с помощью Data Migration Wizard
9. Выбор таблиц для переноса данных с помощью Data Migration Wizard

После этого получим экран, содержащий список таблиц и индексов, подлежащих переносу.
Выбор типа будущей главной формы приложения
13. Выбор типа будущей главной формы приложения

После выбора псевдонима базы данных Oracle из списка псевдонимов определим master-таблицу. В нашем случае это только что созданная таблица CLIENTS:
