Анализ маскирующих преобразований
Все маскирующие преобразования делятся на текстуальные преобразования, преобразования управляющей структуры и преобразования структур данных. Преобразования управляющей структуры в свою очередь делятся на две группы: маскирующие преобразования реструктуризации всей программы и маскирующие преобразования над одной процедурой. Преобразования структур данных в рамках данной работы не рассматривались.
В группе текстуальных маскирующих преобразований рассматриваются преобразования удаления комментариев, переформатирования текста программы и изменения идентификаторов в тексте программы. В группе маскирующих преобразований управляющей структуры, воздействующих на программу в целом, рассматриваются преобразования открытой вставки процедур, выделения процедур, переплетения процедур, клонирования процедур, устранения библиотечных вызовов. В группе маскирующих преобразований маскировки над одной процедурой рассмотрены преобразования внесения непрозрачных предикатов и переменных, внесения недостижимого кода, внесения мёртвого кода, внесения дублирующего кода, внесения тождеств, преобразования сводимого графа потока управления к несводимому, клонирования базовых блоков, развёртки циклов, разложения циклов, переплетения циклов, диспетчеризации потока управления, локализации переменных, расширения области действия переменных, повторного использования переменных, повышения косвенности.
| Int fib(int n) { int a, b, c; a = 1; b = 1; if (n 1; n--) { c = a + b; a = b; b = c; } return c; } | int fib(int n) { int a, b, c, i; long long t; a = 1; b = 1; if (n |
| (a) исходная программа | (b) замаскированная программа |
Рис. 5. Пример применения маскирующего преобразования внесения тождеств
На Рис. 5 показан пример применения маскирующего преобразования внесения тождеств к программе, вычисляющей функцию Фибоначчи. Преобразование основано на малой теореме Ферма
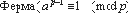
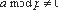
Для этого примера цена равна 3.83, а усложнение программы - 4.85. Расстояние между исходной и замаскированной программой равно 21.
| LC | UC | YC | DC | |
| Исх. процедура fib | 12 | 0 | 0.1111 | 14 |
| Замаскированная fib | 23 | 0 | 0.3086 | 29 |
Другое маскирующее преобразование - введение непрозрачных предикатов - является ключевым для повышения устойчивости других маскирующих преобразований, например, внесения недостижимого кода. Непрозрачным предикатом называется предикат, всегда принимающий единственное значение true или false. При маскировке программы предикат строится таким образом, что его значение известно, но установить по тексту замаскированной программы, является ли некоторый предикат непрозрачным, трудно. В работе рассматриваются методы построения непрозрачных предикатов, использующие динамические структуры данных и булевские формулы.
На основании определения устойчивости маскирующих преобразований, дан-ного выше, становится возможным провести анализ всех опубликованных маскирующих преобразований для выявления их устойчивости по отношению к нашему множеству демаскирующих преобразований и алгоритмов анализа. Мы можем ввести количественную классификацию маскирующих преобразований и выявить наиболее устойчивые маскирующие преобразования. Для этого вводятся - эвристическая оценка CL сложности анализа, которая устанавливает глубину анализа замаскированной программы, необходимого для выполнения демаскирующего преобразования, и эвристическая оценка SL степени поддержки демаскировки, устанавливающая необходимую степень участия человека в процессе демаскировки. Для оценки CL используется шкала, приведённая в таблице 1. Для оценки SL используется шкала: "автоматический анализ" (0 баллов), "полуавтоматический анализ" (1 балл), "ручной анализ с развитой инструментальной поддержкой" (2 балла), "только ручной анализ" (3 балла). Итоговая оценка DL трудоёмкости анализа равна
DC=CL+SL
В нашей работе показано, что для каждого маскирующего преобразования можно предложить автоматический или полуавтоматический метод демаски-ровки, позволяющий приблизить демаскированную программу p` к исходной программе p. При использовании полустатических алгоритмов анализа программ мы исходим из предположения, что для замаскированной программы существует достаточное количество тестовых наборов, обеспечивающее требуемый уровень доверия.
Таким образом можно получить количественную классификацию маскирующих преобразований. Для каждого маскирующего преобразования приводится оценка сложности маскировки и оценка трудоёмкости демаскировки. Значение, получаемое как разность оценки трудоёмкости демаскировки и оценки сложности маскировки, позволяет оценить насколько демаскировка данного маскирующего преобразования сложнее, чем маскировка. Исходя из этого определяются маскирующие преобразования, применение которых неоправдано, например, переформатирование программы, разложение циклов, локализация переменных; методы маскировки, которые следует применять только в комплексе с другими методами, например, изменение идентификаторов, внесение дублирующего кода и методы маскировки, применение которых наиболее оправдано, например, внесение тождеств, переплетение процедур, построение диспетчера, повышение косвенности. Сравнение двух маскирующих преобразований приведено в таблице 3. Через D обозначена разность OC-DL, через ?1 обозначено расстояние между текстами замаскированной и исходной программ fib, а через ?2 - расстояние между текстами демаскированной и исходной программ. Из таблицы следует, что маскирующее преобразование построения диспетчера предпочтительнее, так как, при равных с методом внесения тождеств трудо-затратах на демаскировку, обеспечивает лучшее соотношение усложнения программы к цене преобразования.
| Преобразование | OC | TC | MC | ?1 | CL | SL | DL | ?2 | D | 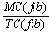 |
| Внесение тождеств | 2 | 3.83 | 4.85 | 21 | 4 - 5 | 2 | 7 | 0 | 5 | 1.27 |
| Построение диспетчера | 2 | 3.83 | 6.14 | 39 | 5 | 2 | 7 | 2 | 5 | 1.60 |
