Разбиение на нити
На этом шаге производится собственно разбиение графа зависимостей по данным на нити. Количество нитей является параметром алгоритма. Так как целью разбиения является получение выигрыша по времени, возникающего из-за увеличения количества событий локальности в каждой нити, то необходимо привязать каждую нить к одному конкретному процессору или, точнее, к конкретному кэшу. Поэтому количество нитей, на которые производится разбиение, обычно равно количеству процессоров в системе.
Алгоритм разбиения состоит в итерировании списка узлов графа, еще не назначенных конкретной нити, и определения нити для какого-либо из узлов (группы таких алгоритмов обычно называются list scheduling). На каждом шаге такой алгоритм делает локально оптимальный выбор. Это значит, что при выборе очередного узла из списка делается попытка присвоить его каждой из имеющихся нитей, после чего выбирается лучшая.
Для того, чтобы иметь возможность оценивать варианты присвоения узла нити, необходимо ввести некоторую оценочную функцию. В нашем случае такая функция содержит время выполнения нити, а также среднеквадратичное отклонение времен выполнения всех нитей. Это следует из того соображения, что в оптимальном разбиении времена выполнения нитей должны быть достаточно близки друг к другу. Возможно включение и других параметров.
При включении узла в какую-либо нить необходимо провести пересчет вре-мени выполнения этой нити. Алгоритм пересчета состоит из следующих шагов:
- Учет времени, необходимого на синхронизацию с другими нитями, если она требуется.
- Учет возникающих событий локальности.
Рассмотрим более подробно каждый из этих шагов.
2.1.3.1. Учет времени на синхронизациюОбрабатываемый на текущем этапе узел может зависеть по данным от некоторых других. В этом случае необходимо дождаться выполнения каждой нити, которые содержит такие узлы. Порядок обхода узлов в списке должен быть таков, чтобы гарантировалось, что все такие узлы уже были распределены на нити. Для этого можно обходить узлы в естественном порядке, то есть так, как они расположены в последовательной программе, либо выполнить тополо-гическую сортировку графа зависимостей по данным.
Еще раз подчеркнем, что иерархичность графа обеспечивает то, что он является ациклическим.
Таким образом, к моменту обработки некоторого узла все узлы, от которых он зависит по данным, уже распределены на нити. Если какие-либо из таких узлов находятся в других нитях, то перед выполнением текущего узла необходимо провести синхронизацию со всеми такими нитями. Для того, чтобы осуществить такую синхронизацию, нужно завести по одной общей переменной для каждой нити. Присваивание значения i такой переменной для некоторой нити j означает, что эта нить выполнила узел i. Нить, ждущая результатов вычисления узла i, должна ждать, пока соответствующая общая переменная не примет нужного значения. Пример такой синхронизации показан на Рис. 2.
Времена выполнения каждой из нитей, проводящих синхронизацию, должны быть увеличены соответствующим образом. Нить, пишущая в общую переменную о результатах выполнения узла, дополнительно работает время t1. Нить, ждущая данных от нескольких узлов, ожидает последний из выполняющихся узлов, после чего тратит время t2. Эти времена являются параметрами алгоритма.
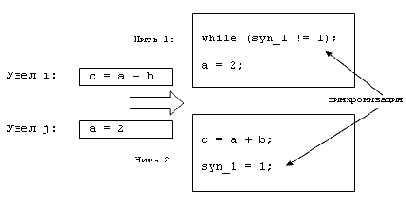
Рис. 2. Пример синзронизации
2.1.3.2. Учет возникающих событий локальности Для учета событий локальности для каждой нити необходимо эмулировать кэш процессора, на котором она выполняется. При распределении текущего узла на какую-либо нить необходимо проверить все переменные, которые читаются либо пишутся узлом, на попадание в кэш. Если попадание произошло, то время выполнения узла должно быть уменьшено на интервал времени t3, также являющийся параметром алгоритма.
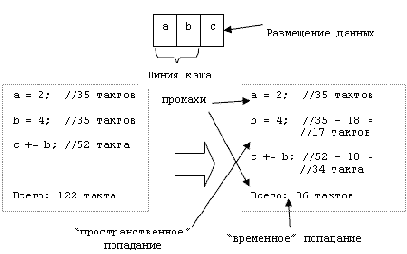
Рис. 3. Пример эмулирования кэша
Для учета событий как временной, так и пространственной локальности необходимо моделирование линий кэша, т.е. помещение в кэш не одной переменной, а некоторого блока памяти, окружающего нужную переменную. Моделирование различных типов кэшей приведет к разным результатам при разделении на нити.
Пример моделирования событий локальности изображен на Рис. 3.
